Методы предварительной обработки текста
Методы предварительной обработки текста
| VAL |
|
Offline

Мэтр, проФАН любви... proFAN of love

Профиль
Группа: Администраторы
Сообщений: 38172
Пользователь №: 1
Регистрация: 6.03.2004

|
Методы предварительной обработки текстаИсточник: https://megapredmet.ru/1-53369.html | QUOTE | Впервые «ручные» техники Text Mining появились в середине 1980-х, а в следующее десятилетие развитие технологий позволило значительно их усовершенствовать. В междисциплинарном смысле Text Mining лежит на стыке поиска информации, Data Mining, машинного самообучения, статистики и компьютерной лингвистики.
Например, текстовые документы практически невозможно преобразовать в табличное представление без потери семантики текста и отношений между сущностями. По этой причине такие документы хранятся в БД без преобразований, как текстовые поля (BLOB-поля). В то же время в тексте скрыто огромное количество информации, но ее неструктурированность не позволяет использовать алгоритмы Data Mining. Решением этой проблемы занимаются методы анализа неструктурированного текста. В западной литературе такой анализ называют Text Mining.
Text Mining часто называют также текстовым дейтамайнингом (text data mining), что отчасти раскрывает взаимосвязь двух этих технологий. Если дейтамайнинг позволяет извлекать новые знания (скрытые закономерности, факты, неизвестные взаимосвязи и т.п.) из больших объемов структурированной информации (хранимой в базах данных), то текстомайнинг — находить новые знания в неструктурированных текстовых массивах.
В этом смысле Text Mining добавляет к технологии data mining дополнительный этап — перевод неструктурированных текстовых массивов в структурированные. После чего данные могут обрабатываться с помощью стандартных методов data mining.
Методы анализа в неструктурированных текстах лежат на стыке нескольких областей: Data Mining, обработка естественных языков, поиск информации, извлечение информации и управление знаниями.
Типичные задачи Text Mining включают категоризацию, кластеризацию текстов, извлечение концептов и объектов, создание таксономий, смысловой анализ, обобщение документации и моделирование объектов, то есть установление связей между различными известными объектами. Анализ текстов включает себя извлечение информации и лингвистический анализ для выявления частоты вхождений различных слов, выявление шаблонов, расставление тэгов и аннотирование, техники Data Mining, включая анализ связей и ассоциаций, визуализацию и прогностический анализ. В конечном счете, общая цель всего этого состоит в том, чтобы превратить текст в данные, доступные для анализа. |
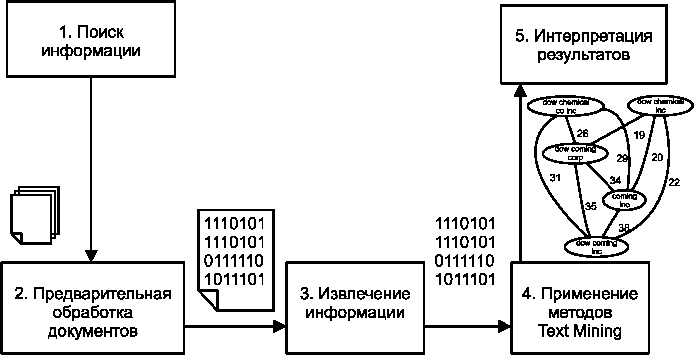
| QUOTE | громное количество информации скапливается в многочисленных текстовых базах, хранящихся в личных ПК, локальных и глобальных сетях. И объем этой информации стремительно увеличивается. Чтение объемных текстов и поиск в гигантских массивах текстовых данных малоэффективны, поэтому становятся все более востребованными решения Text Mining.
ктуальность Text Mining растет по мере того, как людям самых разных профессий приходится принимать решения на базе анализа большого объема неструктурированных и слабоструктурированных текстов (рис. 1).
|
Присоединённое изображение
--------------------
|
|
|
| VAL |
|
Offline
Мэтр, проФАН любви... proFAN of love
Профиль
Группа: Администраторы
Сообщений: 38172
Пользователь №: 1
Регистрация: 6.03.2004
|
| QUOTE | Поиск информации. На первом шаге необходимо идентифицировать, какие документы должны быть подвергнуты анализу, и обеспечить их доступность.
Предварительная обработка документов. На этом шаге выполняются простейшие, но необходимые преобразования с документами для представления их в виде, с которым работают методы Text Mining. Целью таких преобразований является удаление лишних слов и придание тексту более строгой формы.
Извлечение информации. Извлечение информации из выбранных документов предполагает выделение в них ключевых понятий, над которыми в дальнейшем будет выполняться анализ.
Применение методов Text Mining. На данном шаге извлекаются шаблоны и отношения, имеющиеся в текстах. Данный шаг является основным в процессе анализа текстов.
Интерпретация результатов. Последний шаг в процессе обнаружения знаний предполагает интерпретацию полученных результатов. Как правило, интерпретация заключается или в представлении результатов на естественном языке, или в их визуализации в графическом виде.
Визуализация также может быть использована как средство анализа текста. Для этого извлекаются ключевые понятия, которые и представляются в графическом виде. Такой подход помогает пользователю быстро идентифицировать главные темы и понятия, а также определить их важность.
Важная задача технологии Text Mining связана с извлечением из текста его характерных элементов или свойств, которые могут использоваться как метаданные документа, ключевых слов, аннотаций. Другая важная задача состоит в отнесении документа к некоторым категориям из заданной схемы их систематизации. Text Mining также обеспечивает новый уровень семантического поиска документов.
Возможности современных систем Text Mining могут применяться при управлении знаниями для выявления шаблонов в тексте, для автоматического «выталкивания» или размещения информации по интересующим пользователей профилям, создавать обзоры документов |
--------------------
|
|
|
1 Пользователей читают эту тему (1 Гостей и 0 Скрытых Пользователей)
0 Пользователей:



 Помощь
Помощь
 Поиск
Поиск
 Участники
Участники
 Календарь
Календарь
 Фотогалерея
Фотогалерея
 Студенческий форум -> Студенческие форумы НИЯУ МИФИ -> Авторские публикации разных лет -> Международный конгресс юмористов (в Питере) + Text mining
Студенческий форум -> Студенческие форумы НИЯУ МИФИ -> Авторские публикации разных лет -> Международный конгресс юмористов (в Питере) + Text mining